1. Flashclaw: LLM Timeout Optimization
##Problem Statement
Users previously encountered scenarios where Flashclaw would hang for an extended period after an input, eventually returning an
LLM Timeout error. This was primarily due to latency within the message gateway.##The Solution
We have optimized the Flashclaw Message Gateway to enhance processing efficiency:
-
Accelerated Forwarding: Improved the speed at which user inputs are routed to the underlying Large Language Models (LLM).
-
Latency Reduction: Minimized the overhead between the input and the start of the model's response, significantly reducing the probability of timeout errors.
##Core Value
-
Improved Responsiveness: Users experience faster turnarounds with significantly fewer interruptions caused by gateway delays.
2. SuperAgent: Fee Preview for Third-Party Tool Usage
##Background
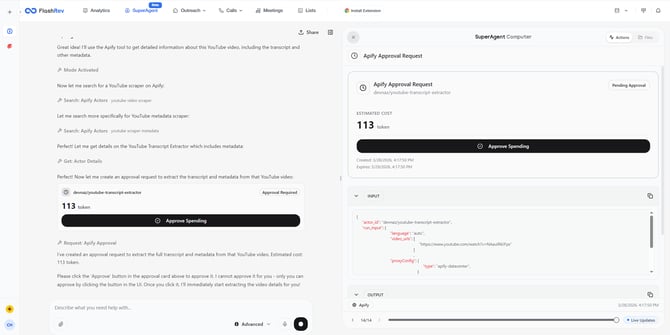
SuperAgent utilizes connected MCP services or built-in tools like Apify—a marketplace for web scraping (TikTok, Amazon, Google Maps, etc.)—to handle complex research and data extraction tasks.
##Feature Update
We have introduced a Fee Preview & Confirmation workflow for these high-cost integrations:
-
Token Pre-calculation: Before invoking a service like Apify, SuperAgent estimates the potential Token consumption based on the task complexity.
-
User Confirmation: The system requests user approval of the estimated cost before proceeding, ensuring full transparency of the operational expenses.
##Core Value
-
Cost Transparency: Users gain clear insight into the costs associated with premium third-party tool usage.
-
Granular Control: Prevents unintentional high-cost operations by putting the final "Go/No-Go" decision in the user's hands.
3. Slide Agent: Generation Architecture Refactoring
##Problem Statement
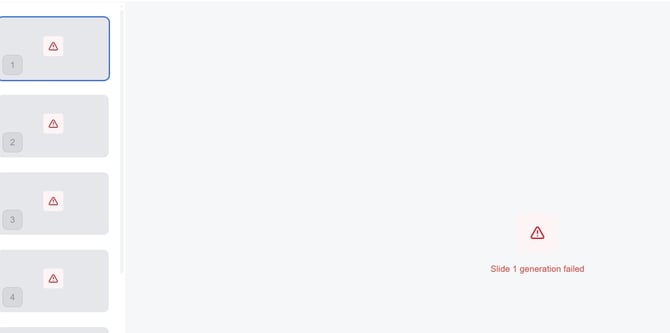
The previous "URL-based fetching" method, where the AI model was sent a cloud storage link (COS) to fetch content, proved unstable.
-
Errors: Frequent
INVALID_ARGUMENTerrors occurred when the model failed to access private or complex URLs. -
Latency: Large file parsing often results in timeouts or a perceived "system hang" due to lack of real-time feedback.
##The Solution: Server-side Stream Upload
We have completely overhauled the data pipeline to ensure 100% reliability:
-
From Fetching to Pushing: Instead of relying on the model to fetch data from an external URL, the FlashRev backend now handles the file download and pre-processing, pushing the raw Byte Stream directly to the model.
-
Zero-Fetch Error: By eliminating external URL dependency, we've achieved a 99.9% generation success rate, completely bypassing model-side connectivity issues.
-
Smart Validation: The system now verifies file integrity before processing, ensuring that only valid data enters the generation queue.